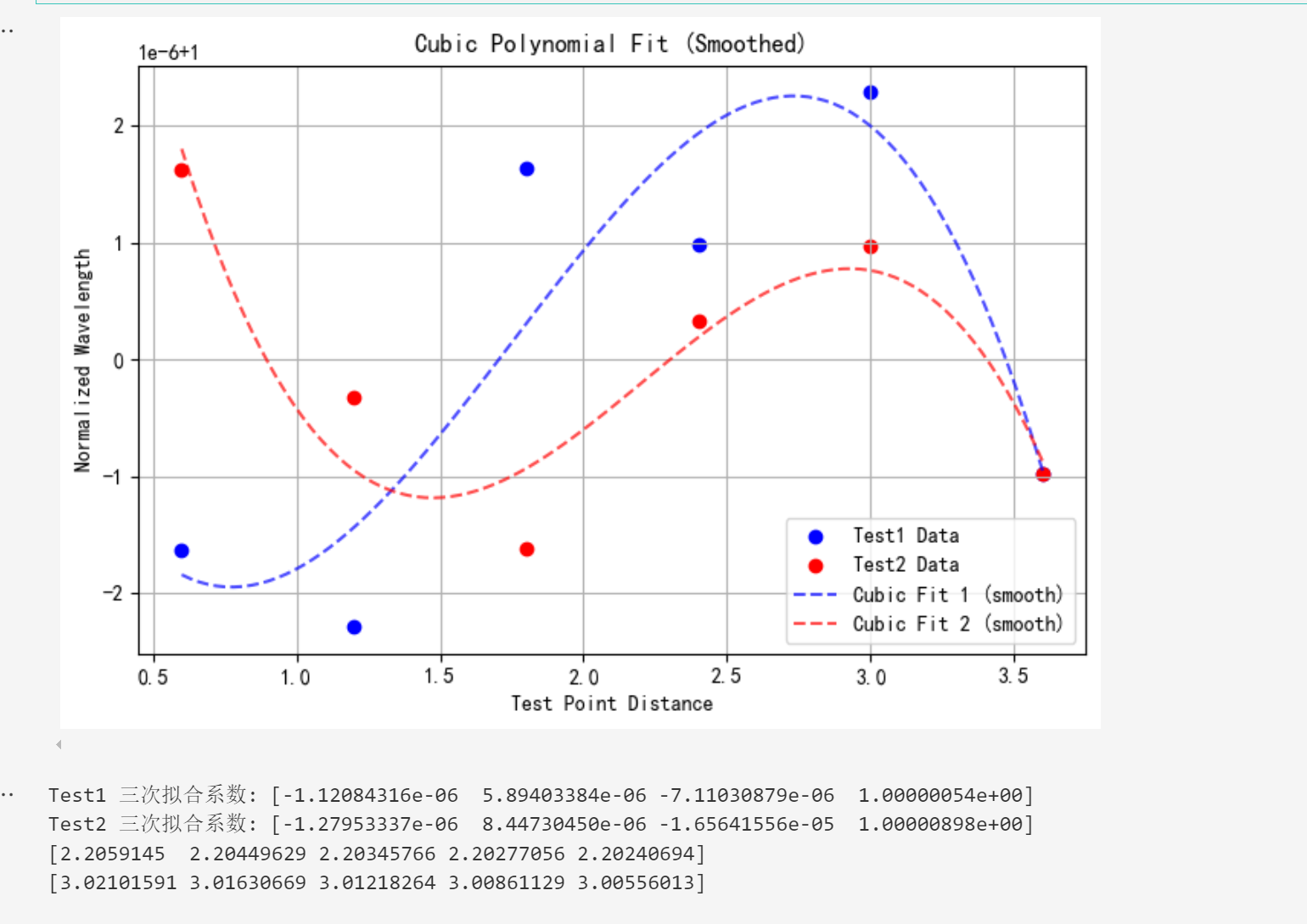
锁存器
SR锁存器
SR锁存器的两种组成方式
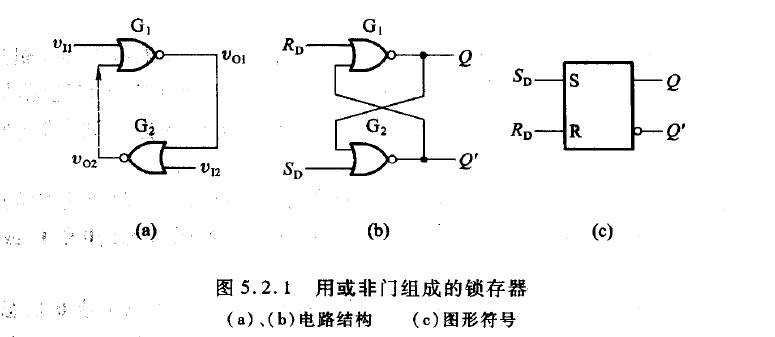
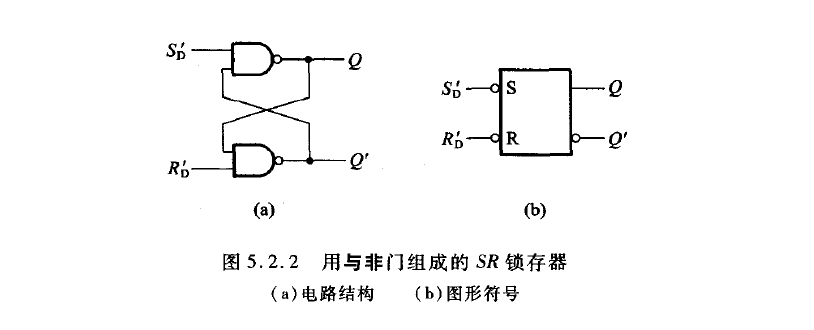
无论是哪一种SR锁存器,其底层逻辑都是一致的,可以用以下几句话概括:
- 或非门SR锁存器是正逻辑,与非门SR锁存器是反逻辑。
- 当S=R=0时,锁存器输出保持上一个时刻的输出。(对于反逻辑而言。即S’=R’=1)
- 当S=1,R=0时,进入Set模式,输出端置1。
- 当S=0,R=1时,进入Reset模式,输出端置0。
- 当S=R=1时,分以下两种情况:
a. 对于正逻辑锁存器,均输出0
b. 对于反逻辑锁存器,均输出1
这种情况下,当S,D的信号同时变为0后状态不定。
由此可知,对于正常的情况,我们应当保证S·R=0的约束条件。但是要注意理解,当情况5中下一时刻S与R错开变化,我们其实是可以预测下一时刻电路的输出状态的。
下面是正逻辑SR锁存器的真值表
| S | R | Q | |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 1 |
| 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 0 |
| 1 | 1 | 0 | 0 |
下面是反逻辑SR锁存器的真值表
| (S’) | (R) | (Q) | (Q^*) |
|---|---|---|---|
| 1 | 1 | 1 | 1 |
| 1 | 1 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 |
| 0 | 0 | 1 | 1 |
| 0 | 0 | 0 | 1 |
注意这两种触发器真值表的最后两行不是一样的!另外这个电路要自己画一遍。
触发器
电平触发
电平触发的SR触发器
当触发信号CLK变成高电平后,SR锁存器才正常工作,否则SR锁存器将保持原有输出,无论S与R的输入情况如何。具有这种性质的触发器就是电平触发器。
这种触发器的操作效果可以这样表述:
- CLK=0,电路保持原状态输出
- CLK=1,电路变成SR锁存器电路。
电平触发的触发器有这样的作用特点: - 只有当CLK有效的时候才需要看输入情况.
- 在CLK=1的全部时间里,SR的状态都会引起输出变化;CLK回到0后,触发器保存着前一瞬间的状态。
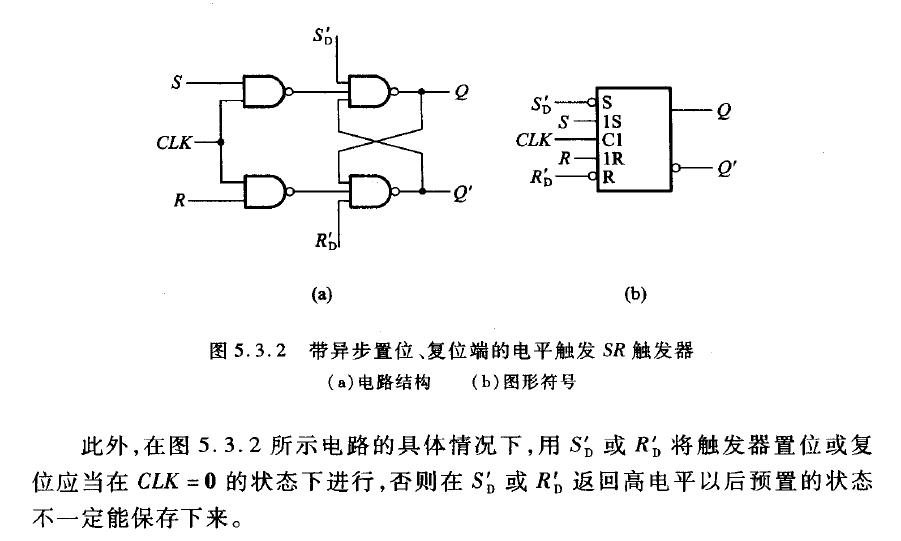
下面介绍带异步置位复位端口的电平触发SR触发器。
他的思路也很简单:在原有的电平触发SR触发器的基础上,添加两个优先级更高的信号S’,R’,若这两个信号有效,只要相应地将其置为1或0即可;当这两个信号无效,则进入一般的电平触发SR触发器
下面给出SR触发器的逻辑图:![同步SR触发器]()
![异步SR触发器]()
在CLK=1时,同步SR触发器的真值表与一般SR触发器完全相同;在CLK=0时,电路出于保持状态。
相关真值表此处从略

电平触发的D触发器
D触发器的发明是为了先天地去除可能使得SR触发器中S=R=1的情况的一种设计,它其实就是把
将SR触发器中的输入端利用同一个信号D及其反信号作为输入信号D’作为S和R端输出,得到的就是电平触发的D触发器。
其逻辑图如下: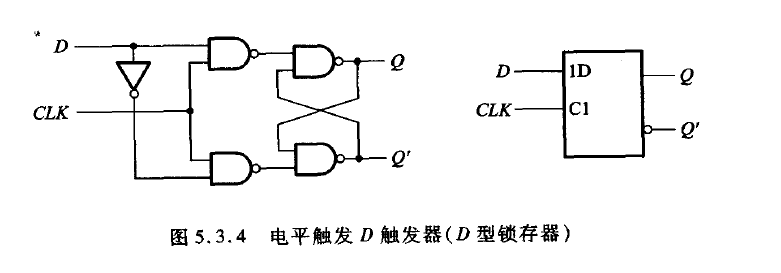
由此可见,这样的方式先天避免了S=R=1的可能性,但是也使得S=R=0变得不可能。为了使电路保持功能完整,我们规定:
CLK定好为低电平时,为D型锁存器的保持态。
边沿触发
我们直接来看一个例子: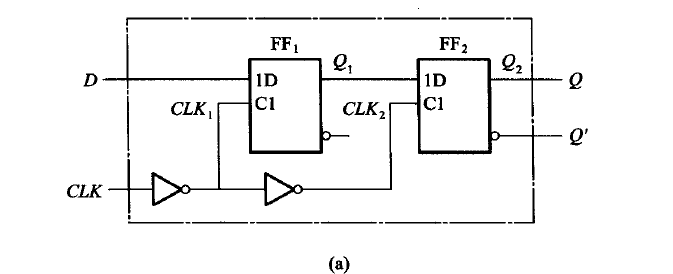
分析以下CLK从0->1(上升沿)的电路变化:
CLK=0时:
- CLK=0,CLK1=1,CLK2=0
- FF1有效,FF2无效
- Q1随着输入信号D同步变化,即Q1=D
- Q=Q2不变(注意,此前我一直以为这是会变化的!)
CLK=1时:
- CLK=1,CLK1=0,CLK2=1
- FF2有效,FF1无效
- Q1=D不再变化
- Q2=Q1=D
由此我们可以知道,这种上升沿边沿触发器有以下特点:
- 触发器的次态输出仅仅取决于上升沿到达前瞬间输入的逻辑状态,在一个时钟周期内上升沿到来前后,输入信号的变化对触发器的次态没有影响
- 从结果上看,以上升沿边沿触发器为例,输出信号只有在CLK信号上升沿到来处才有可能发生变化(分析波形图的时候可以直接判断这些关键节点)
至于下降沿边沿触发其的特点则可以完全对称地总结下来,这里从略。
下面看一下边沿触发方式的判断方法:
- 前非后不非->上升沿(符号不带圈)
- 后非前不非->下降沿(符号带圈)
脉冲触发
主从SR触发器(MSSR触发器)
![MSSR触发器]()
我们来尝试分析以下这个电路: - CLK=0,CLK’=1,主触发器FF1,从触发器FF2均出于保持态。(虽然FF2的时钟信号是有效的,由于前一级的信号不会变,所以这一级的信号也不变,体现“主从”关系)
- CLK->1,上升沿到来时,Qm随着S和R的变化而变化,而从触发器保持原来的状态不变。
- CLK->0,下降沿到来时,从触发器的输出Q被置为此刻Qm的相同状态。
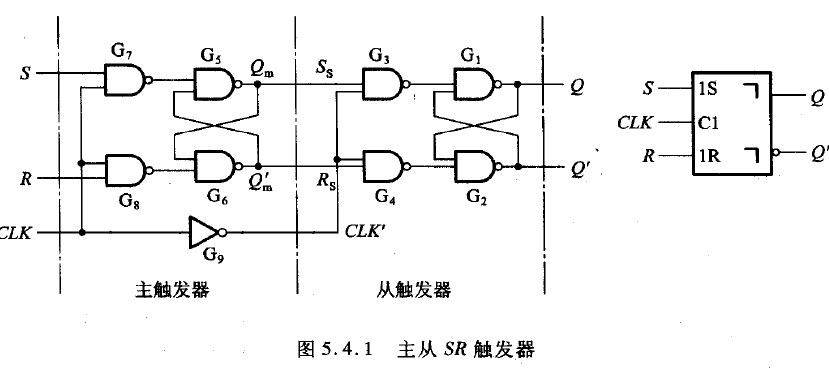
简单来说就是:
- 在一个时钟周期里只有CLK下降沿处(或上升沿,取决于电路结构)可能会发生输出端状态的改变。
- 在脉冲触发中,不能仅仅根据CLK下降沿(或上升沿)到来的前一时刻的输入状态来确定输出端的状态,必须要考虑CLK=1(或0,表示边沿到来前)主触发器的变化。
JK触发器
先来看下这个令人遐想连篇(雾)的触发器的逻辑图,以及教材上对她的解读: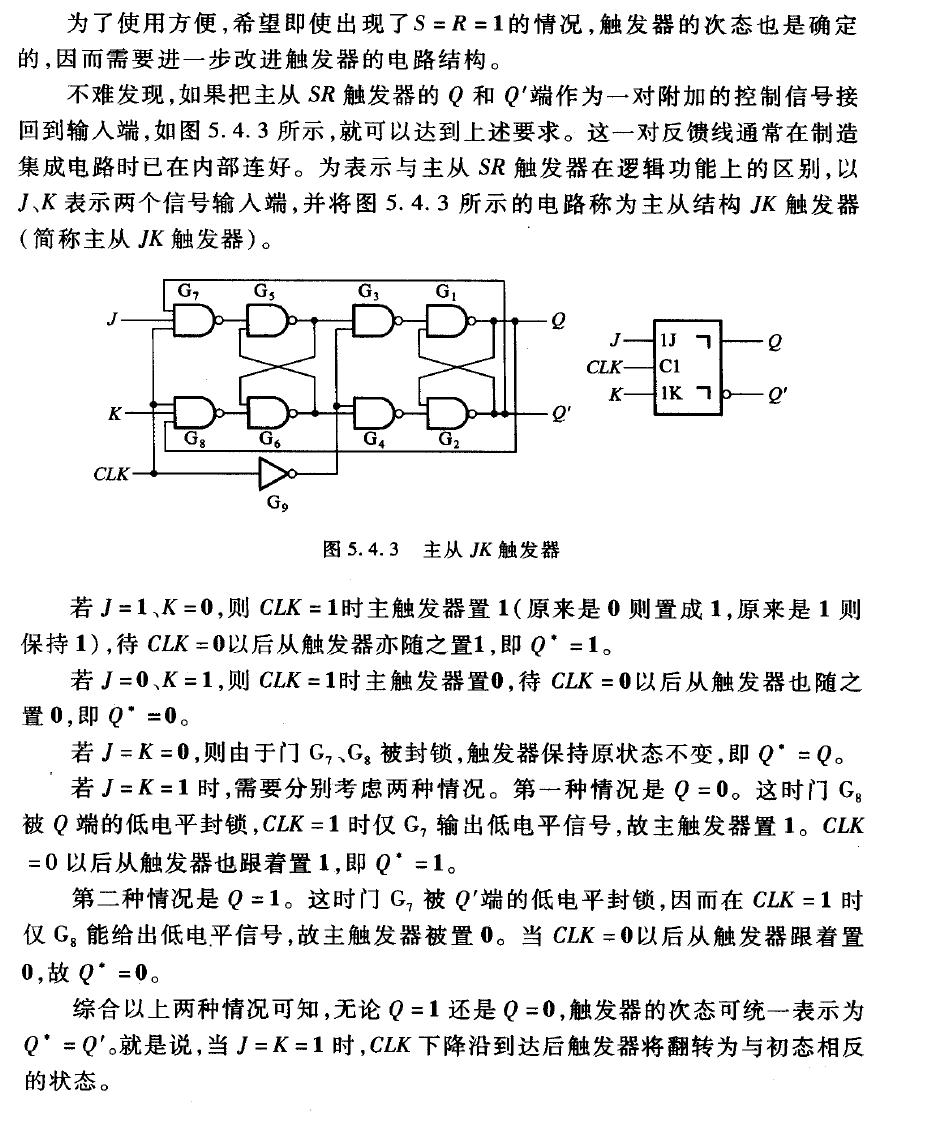
简单来说,JK触发器的逻辑功能就是:
- CLK下降沿(或上升沿)触发
- 触发时,J=S,K=R
- 唯一的区别:J=R=1时,确定次态变为当前态的反态
按逻辑功能分类的触发器
触发器的逻辑表达式:
- SR触发器:
- JK触发器:
- T触发器:
- D触发器: